
Resumo Executivo
Adicionar roteamento de conformidade a uma stack técnica em produção representa um conjunto específico de restrições de engenharia para exchanges e carteiras de criptomoedas. À medida que os mandatos de relatórios regulatórios mudam globalmente, o requisito por sistemas automatizados de triagem e sinalização de transações tornou-se um item padrão no backlog. Este guia descreve um caminho de integração objetivo para engenheiros de backend e arquitetos de sistemas que implantam camadas de conformidade. Desde as avaliações iniciais de handshake de protocolo até o tratamento da sincronização de dados de nós multi-chain, esta documentação detalha os ajustes arquiteturais necessários para provisionar pipelines de API seguros e de baixa latência. Ao configurar workers estáveis de monitoramento de transações e aplicar lógica de pontuação de risco on-chain, as equipes de engenharia podem atender aos requisitos de auditoria enquanto mantêm o throughput de processamento esperado.
Principais Insights
A transição de verificações manuais de conformidade para fluxos de trabalho automatizados orientados por API requer planejamento arquitetural direto. Dados recentes de telemetria mostram que 68% das plataformas de ativos digitais enfrentam starvation de threads ou bloqueios de banco de dados durante a sincronização de nós em alto volume, caso suas camadas de conformidade careçam de cache adequado [1]. Incorporar protocolos de triagem de contratos inteligentes diretamente no caminho de execução de transações reduz as taxas de incidentes. As equipes técnicas geralmente focam em interoperabilidade, chamando endpoints unificados de API AML/KYT para processar formatos de ledger distintos. O requisito de base é configurar um serviço assíncrono e tolerante a falhas, capaz de resolver status de transações criptográficas em milissegundos. As ferramentas empresariais atuais, incluindo APIs fornecidas pela BlockSec, oferecem aos desenvolvedores esquemas de integração definidos, eliminando a sobrecarga de manutenção necessária para construir e atualizar internamente utilitários proprietários de parsing de ledger.
Pré-Integração: Arquitetura e Requisitos de Sistema
Avaliar a compatibilidade de protocolos, padronizar payloads de dados e verificar protocolos de privacidade de dados são tarefas básicas antes de escrever código de produção. As equipes de engenharia executam auditorias de sistema para mapear as capacidades de roteamento internas em relação aos endpoints externos de conformidade, reduzindo limites de API downstream e vazamentos de dados.
Avaliando a Compatibilidade da Stack Tecnológica Existente para Integração com API REST
Antes de iniciar a fase de implementação, as equipes de engenharia avaliam os protocolos de comunicação da infraestrutura atual para verificar a compatibilidade com provedores terceiros de dados de conformidade. A Phalcon Compliance expõe suas capacidades por meio de APIs RESTful padrão, que funcionam bem para operações sem estado, como consultar um único endereço de carteira para obter um indicador de risco ou enviar uma transação para triagem KYT. Para manter a latência previsível em ambientes de alto volume, os arquitetos de sistema focam em conexões HTTP/2 keep-alive, seleção de endpoints regionais e respostas armazenadas em cache de borda para consultas repetidas, em vez de substituir a camada de transporte. Os balanceadores de carga e topologias de microsserviços existentes devem ser revisados para confirmar que conexões TLS de longa duração, pooling de conexões e cabeçalhos de limite de taxa por rota sejam tratados corretamente em toda a malha de serviços.
Definindo Requisitos de Payload de API e Eventos de Webhook
Uma requisição padrão inclui o hash da transação, endereços de origem e destino, contrato do ativo e ID da chain. Para rastreamento contínuo de risco de endereços, a integração não depende de um fluxo genérico de Webhook de "atualização". Em vez disso, a Phalcon Compliance oferece uma capacidade dedicada de Monitor: as equipes de engenharia habilitam o Monitor nos endereços de interesse, e a plataforma reanalisará automaticamente esses endereços em um cronograma dinâmico. Quando uma nova regra de risco é acionada, ou uma regra anteriormente acionada é removida, a plataforma entrega um alerta por meio dos Canais de Notificação configurados pelo usuário. O Monitor reutiliza os Risk Engines e os Canais de Notificação existentes da conta, portanto, nenhum esquema de Webhook separado, camada de idempotência ou lógica de deduplicação de UUID de eventos é necessário do lado do integrador para esse fluxo.
Restrições de Segurança, Criptografia e Privacidade de Dados (SOC2/GDPR)
Conectar APIs de terceiros requer configurações de segurança específicas para atender aos requisitos do SOC2 e do Regulamento Geral de Proteção de Dados. Ao enviar dados de ledger para o exterior, informações de identificação pessoal devem permanecer isoladas das solicitações de metadados on-chain. Rotinas de hashing criptográfico ou tokenização são aplicadas a IDs de usuários internos antes da transmissão externa. Todos os dados em trânsito são roteados por meio do Transport Layer Security (TLS 1.3), aplicando TLS mútuo (mTLS) para verificação servidor a servidor. As regras de controle de acesso dependem de JSON Web Tokens de curta duração e rotação dinâmica, em vez de chaves de API fixas no código, para limitar o raio de impacto em caso de exposição de credenciais.
Fluxo de Trabalho de Integração de API Passo a Passo
Uma sequência de integração bem definida garante monitoramento estável de transações, mapeamento preciso de dados e roteamento de fallback que evita a degradação do serviço durante congestionamentos de rede. Seguir padrões de implementação padrão permite que os desenvolvedores vinculem books de ordens internos a redes externas de conformidade com segurança.
Etapa 1: Gerenciamento Seguro de Autenticação e Chaves de API
A fase de configuração começa com a definição do limite de autenticação. Armazenar credenciais de API diretamente em arquivos de configuração de aplicação introduz vulnerabilidades imediatas. As equipes de engenharia configuram serviços de vault seguros, como o HashiCorp Vault ou o AWS Secrets Manager, para buscar credenciais em tempo de execução. Para plataformas que suportam autenticação avançada, usar OIDC (OpenID Connect) ou pares de chaves RSA para assinatura de requisições gera prova verificável da origem do payload. Configurar a rotação automatizada de chaves de API dentro de pipelines de CI/CD mantém a segurança de acesso sem tarefas operacionais manuais, impedindo que tokens obsoletos acessem o backend de conformidade.
Etapa 2: Mapeando Dados Internos de Transações para Endpoints AML/KYT
A principal tarefa de engenharia requer a tradução de esquemas internos de banco de dados para o formato específico exigido pelo provedor de conformidade. Esse mapeamento envolve a criação de middleware que extrai entradas de transação de ledgers locais, formata-as conforme as especificações de destino e as roteia para os endpoints de API AML/KYT relevantes. Para melhorar o desempenho geral, os desenvolvedores configuram cron jobs para processamento em lote de registros históricos, mantendo as chamadas de API síncronas restritas às verificações de saque pré-transação. Usar plataformas consolidadas como a BlockSec reduz esse ciclo de engenharia, pois seus esquemas de API aceitam variáveis padrão multi-chain, diminuindo em aproximadamente 40% o trabalho de mapeamento de middleware necessário.
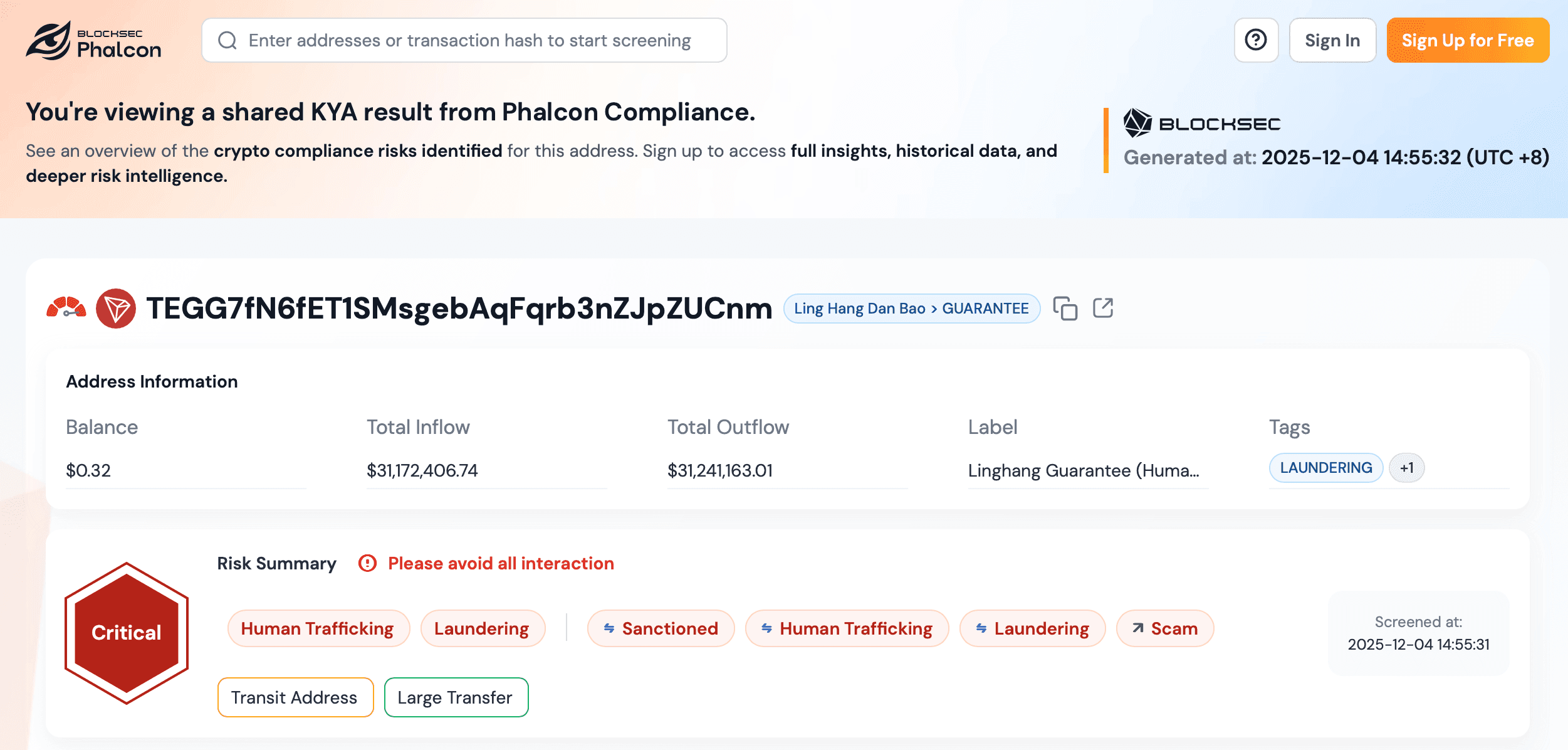
Etapa 3: Habilitando o Monitor para Alertas Contínuos de Risco de Endereços
A triagem inicial de KYT captura apenas o estado de risco de um endereço no momento da chamada. Para cobrir o caso em que um endereço anteriormente limpo interage posteriormente com uma entidade sinalizada, os desenvolvedores habilitam o recurso Monitor nos endereços que precisam de supervisão contínua — por exemplo, endereços de depósito de usuários de alto valor, hot wallets ou contrapartes de grandes negociações OTC. O Monitor pode ser habilitado na página de detalhes do endereço, no menu de ação da lista de endereços ou programaticamente por meio dos endpoints de gerenciamento do Monitor em Pricing & Usage → Data Management → Monitors. Uma vez habilitado, o endereço exibe um badge de status Monitoring, e a plataforma o reanalisará em uma frequência dinâmica. Os alertas são disparados apenas em transições reais de estado de risco (uma nova regra acionada ou uma regra existente removida) e são entregues pelos Canais de Notificação já configurados para a conta, mantendo o backend do integrador livre de loops de polling ou tratamento de eventos duplicados. A capacidade é regida pelo plano: Essential e Scale incluem 1 endereço monitorado com níveis pagos de complemento (10 / 20 / 40 / 80 / 120 / 200), as contas Free e Credits recebem um período de avaliação único de 7 dias, e os contratos Enterprise definem capacidade personalizada.
Etapa 4: Agindo sobre Respostas de Risco da API com Lógica de Tratamento Downstream
Assim que a API de conformidade retorna uma avaliação de risco para uma transação ou endereço, o provedor de serviços integrador é responsável por traduzir esse resultado em ações concretas downstream. A resposta da API em si não bloqueia nem move fundos — ela apenas reporta a classificação de risco, as regras acionadas e os metadados associados. As equipes de engenharia constroem uma camada de decisão dedicada que consome essa resposta e mapeia cada nível de risco para uma ação operacional predefinida.
As ações downstream típicas incluem:
-
Reembolso de depósitos recebidos identificados como originários de endereços sancionados ou de alto risco, devolvendo os ativos ao endereço de origem antes de serem creditados ao saldo interno do usuário.
-
Congelamento da conta de usuário afetada ou do saldo da carteira, suspendendo saques e negociações até que a revisão manual seja concluída.
-
Roteamento da transação para uma fila de revisão manual, onde os responsáveis pela conformidade inspecionam as regras acionadas e decidem se liberam, rejeitam ou escalam o caso.
-
Bloqueio da solicitação de saque de saída na fase de pré-transmissão, quando o endereço de destino apresenta uma pontuação de risco inaceitável.
Cada ação deve ser acionada de forma idempotente com base no payload de resposta da API (e em quaisquer alertas subsequentes do Monitor para o mesmo endereço), com registro completo de auditoria para que cada decisão automatizada possa ser reconstruída para fins de relatórios regulatórios.
Armadilhas Comuns de Integração e Resolução de Problemas
As equipes de engenharia enfrentam regularmente problemas operacionais, incluindo limitação de taxa de API, reorganizações de chain e taxas elevadas de falsos positivos, que requerem ajustes programáticos. Escrever lógica rigorosa de tratamento de erros e modificar parâmetros de risco mantém os sistemas automatizados precisos e estáveis durante períodos de alto volume de transações.
Mitigando Limites de Taxa de API e Gargalos de Alta Latência
Atingir os limites de taxa de API ocorre com frequência durante a volatilidade do mercado, quando as filas de transações se expandem. Quando a infraestrutura atinge um limite, a API do provedor retorna uma resposta HTTP 429 Too Many Requests. Para corrigir isso, os engenheiros constroem camadas de throttling do lado do cliente e de cache local para valores estáticos, como endereços de contrato previamente verificados. Configurar o Redis ou o Memcached para armazenar pontuações de risco recentes reduz solicitações HTTP de saída duplicadas. Configurar threads de worker paralelos e ajustar o pooling de conexões de banco de dados garante que o sistema maximize o throughput disponível sem acionar os limites rígidos do provedor externo.
Reduzindo Falsos Positivos por Meio de Regras Personalizadas de Pontuação de Risco
Os algoritmos de risco padrão frequentemente retornam falsos positivos, restringindo saques de usuários comuns e aumentando os tickets de suporte manual. As equipes técnicas ajustam os parâmetros de pontuação de risco on-chain passando variáveis de metadados específicas pelo corpo da API. Ao cruzar sinalizadores de risco externos com análises de sessão internas, o sistema aplica declarações condicionais para sobrescrever regras rígidas para contas institucionais estabelecidas e verificadas. Definir limites de threshold locais permite que a equipe de desenvolvimento ajuste a sensibilidade dos alertas, ajudando os filtros de backend a distinguir entre transferências maliciosas reais e interações padrão com contratos inteligentes.
Otimizações Técnicas Avançadas para Pipelines de Dados
Escalar uma configuração de conformidade requer engenharia de dados, integração com pipelines de CI/CD, análise baseada em grafos e considerações de hospedagem localizada. Aplicar métodos padrão de implantação permite que as equipes técnicas façam o parsing de dados de ledger enquanto aplicam segurança operacional rigorosa e controle de dados.
Automatizando Fluxos de Trabalho de Escalonamento por meio de Pipelines de CI/CD
Atualizar regras de conformidade requer adicionar testes unitários e de integração ao pipeline de implantação. Quando os engenheiros de backend modificam parâmetros de risco ou atualizam a lógica de parsing de API, o novo código é executado contra conjuntos de dados históricos de transações em um ambiente de staging. As equipes escrevem scripts para Jenkins ou GitHub Actions para executar esses testes de regressão automaticamente. Se um commit de código gerar um aumento anormal nas transações sinalizadas durante a simulação, o pipeline bloqueia o merge request. Essa configuração de infraestrutura como código verifica se as modificações no mecanismo de risco passam pela validação matemática antes da implantação em produção.
Utilizando Estruturas de Dados em Grafos para Análise Profunda de Carteiras
Rastrear padrões de ofuscação de criptomoedas, incluindo coin mixers ou bridges cross-chain, ultrapassa os limites de consulta de bancos de dados relacionais. As integrações de engenharia frequentemente utilizam ferramentas de banco de dados em grafos (por exemplo, Neo4j) para mapear transações com múltiplos saltos e vínculos entre entidades. Ao sincronizar a inteligência de conformidade externa com um esquema de grafo local, os desenvolvedores executam consultas em múltiplas camadas com baixa latência. As ferramentas desenvolvidas pela BlockSec suportam exportações de dados baseadas em grafos, permitindo que as equipes de backend rastreiem caminhos de execução algorítmica em nós conectados e identifiquem padrões de ameaças programadas sem grande sobrecarga computacional.
Avaliando Implantações em Ambiente Privado para Soberania de Dados
Para organizações sujeitas a leis locais de soberania de dados, o envio de registros internos de transações para APIs em nuvem multi-tenant é restrito. Nesses casos, as equipes de engenharia provisionam configurações de ambiente privado ou on-premise. Isso requer hospedar as instâncias de nós e os contêineres de análise do provedor de conformidade dentro de clusters Kubernetes localizados ou nuvens privadas virtuais (VPCs) restritas. Embora essa configuração aumente a manutenção operacional necessária para patches de software e sincronização de dados históricos, ela fornece garantia matemática de que metadados específicos de ledger permanecem fora das rotas públicas da internet.
FAQ Técnico: Integração de Conformidade em Blockchain
Resolver questões técnicas padrão sobre latência, ingestão de dados históricos, roteamento de API multi-chain e modelos de implantação de infraestrutura auxilia as equipes de desenvolvimento empresarial no planejamento de sistemas. Estas respostas básicas descrevem os requisitos arquiteturais para suportar operações de ledger em alto volume e em conformidade.
Quanta latência o monitoramento KYT em tempo real adiciona às transações?
Em arquiteturas que utilizam streaming gRPC e cache Redis, a latência de consulta em tempo real é medida entre 50 e 150 milissegundos. Se o backend depende de requisições REST API síncronas roteadas por zonas de disponibilidade distantes sem pooling de conexões, os tempos de resposta podem ultrapassar 500 milissegundos, o que frequentemente aciona timeouts de execução em motores de correspondência de alta frequência.
Qual é o método mais eficiente para sincronizar dados históricos on-chain?
Para análise histórica, os engenheiros evitam a paginação REST padrão e solicitam exportações de dados em massa. Enviar arquivos Apache Parquet ou CSV diretamente para um data lake interno (como AWS S3 ou Snowflake) viabiliza a ingestão paralela de dados. Essa abordagem evita bloqueios por limite de taxa HTTP e reduz o total de horas de processamento necessárias para a sincronização histórica inicial.
Como gerenciamos o roteamento de conformidade multi-chain dentro de uma única API?
As plataformas de conformidade atuais fornecem uma camada de abstração unificada. Os desenvolvedores enviam o payload JSON padrão e incluem um inteiro específico network_id ou chain_identifier. O balanceador de carga do provedor externo lê essa variável e roteia a verificação para o cluster de nós correspondente (por exemplo, nós compatíveis com EVM versus nós UTXO), retornando um esquema padronizado independentemente do formato do blockchain de destino.
As ferramentas de inteligência de conformidade podem ser implantadas totalmente on-premise?
Sim. Os provedores empresariais fornecem pacotes de implantação por meio de imagens Docker ou Helm charts configurados para clusters Kubernetes locais. Isso isola todo o processamento de transações e os cálculos de risco dentro da sub-rede privada da organização, completamente desconectada de gateways de internet pública, atendendo aos rigorosos requisitos de auditoria regulatória e de privacidade de dados.
Conclusão
Configurar uma API de conformidade em blockchain requer design arquitetural estruturado, configurações de segurança específicas e resiliência no nível da aplicação. Ao verificar a compatibilidade de protocolos, mapear esquemas de dados com precisão e escrever código rigoroso de tratamento de erros, as equipes técnicas evitam limites operacionais comuns. Implementações que utilizam testes de CI/CD, consultas em banco de dados de grafos e camadas de cache estabilizam o desempenho do sistema sob carga. Integrar plataformas voltadas para desenvolvedores como a BlockSec permite que os departamentos de engenharia configurem esses pipelines de API de forma eficiente, fornecendo os utilitários de backend necessários para atender às verificações regulatórias em ambientes ativos de ativos digitais.



