
Resumen Ejecutivo
Agregar enrutamiento de cumplimiento normativo a un stack técnico en producción representa un conjunto específico de restricciones de ingeniería para los exchanges y billeteras de criptomonedas. A medida que los mandatos de informes regulatorios evolucionan a nivel global, el requisito de sistemas automatizados de filtrado y marcado de transacciones se ha convertido en un elemento estándar del backlog. Esta guía describe una ruta de integración objetiva para ingenieros de backend y arquitectos de sistemas que despliegan capas de cumplimiento. Desde las evaluaciones tempranas del protocolo de enlace hasta el manejo de la sincronización de datos de nodos multi-chain, esta documentación detalla los ajustes arquitectónicos necesarios para aprovisionar pipelines de API seguros y de baja latencia. Al configurar workers estables de monitoreo de transacciones y aplicar lógica de puntuación de riesgo on-chain, los equipos de ingeniería pueden cumplir con los requisitos de auditoría mientras mantienen el rendimiento de procesamiento esperado.
Perspectivas Clave
Pasar de las verificaciones de cumplimiento manuales a flujos de trabajo automatizados impulsados por API requiere una planificación arquitectónica directa. Los datos de telemetría recientes muestran que el 68% de las plataformas de activos digitales experimentan inanición de hilos o bloqueos de bases de datos durante la sincronización de nodos de alto volumen si sus capas de cumplimiento carecen de caché adecuado [1]. Incorporar protocolos de filtrado de contratos inteligentes directamente en la ruta de ejecución de transacciones reduce las tasas de incidentes. Los equipos técnicos generalmente se enfocan en la interoperabilidad, llamando a endpoints unificados de API AML/KYT para procesar formatos de libro mayor distintos. El requisito base es configurar un servicio asíncrono y tolerante a fallos capaz de resolver estados criptográficos de transacciones en milisegundos. Las herramientas empresariales actuales, incluidas las APIs proporcionadas por BlockSec, ofrecen a los desarrolladores esquemas de integración definidos, eliminando la sobrecarga de mantenimiento requerida para construir y actualizar internamente utilidades propietarias de análisis de libro mayor.
Pre-Integración: Arquitectura y Requisitos del Sistema
Evaluar la compatibilidad de protocolos, estandarizar los payloads de datos y verificar los protocolos de privacidad de datos son tareas básicas antes de escribir código de producción. Los equipos de ingeniería ejecutan auditorías del sistema para mapear las capacidades de enrutamiento interno contra los endpoints externos de cumplimiento, reduciendo los límites de API downstream y las filtraciones de datos.
Evaluación de la Compatibilidad del Stack Tecnológico Existente para la Integración de API REST
Antes de iniciar la fase de implementación, los equipos de ingeniería evalúan los protocolos de comunicación de la infraestructura actual para verificar la compatibilidad con proveedores externos de datos de cumplimiento. Phalcon Compliance expone sus capacidades a través de APIs RESTful estándar, que funcionan bien para operaciones sin estado como consultar una dirección de billetera individual para obtener un indicador de riesgo o enviar una transacción para el filtrado KYT. Para mantener la latencia predecible en entornos de alto volumen, los arquitectos de sistemas se enfocan en conexiones keep-alive HTTP/2, selección de endpoints regionales y respuestas con caché en el borde para consultas repetidas, en lugar de reemplazar la capa de transporte. Los balanceadores de carga existentes y las topologías de microservicios deben revisarse para confirmar que las conexiones TLS de larga duración, el connection pooling y los encabezados de límite de tasa por ruta se manejan correctamente a través del service mesh.
Definición de Requisitos de Payload de API y Eventos de Webhook
Una solicitud estándar incluye el hash de la transacción, las direcciones de origen y destino, el contrato del activo y el ID de la cadena. Para el seguimiento continuo del riesgo de direcciones, la integración no depende de un flujo genérico de Webhook de "actualización". En cambio, Phalcon Compliance proporciona una capacidad dedicada de Monitor: los equipos de ingeniería habilitan Monitor en las direcciones que les interesan, y la plataforma re-analiza automáticamente esas direcciones en un horario dinámico. Cuando se activa una nueva regla de riesgo, o se elimina una regla previamente activada, la plataforma entrega una alerta a través de los Canales de Notificación configurados por el usuario. Monitor reutiliza los Motores de Riesgo y los Canales de Notificación existentes de la cuenta, por lo que no se requiere un esquema de Webhook separado, una capa de idempotencia o lógica de deduplicación de UUID de eventos en el lado del integrador para este flujo.
Restricciones de Seguridad, Cifrado y Privacidad de Datos (SOC2/GDPR)
Conectar APIs de terceros requiere configuraciones de seguridad específicas para satisfacer los requisitos de SOC2 y el Reglamento General de Protección de Datos. Al enviar datos del libro mayor al exterior, la información de identificación personal debe permanecer aislada de las solicitudes de metadatos on-chain. Las rutinas de hash criptográfico o tokenización se aplican a los IDs de usuario internos antes de la transmisión externa. Todos los datos en tránsito se enrutan a través de Transport Layer Security (TLS 1.3), aplicando TLS mutuo (mTLS) para la verificación servidor a servidor. Las reglas de control de acceso dependen de JSON Web Tokens de corta duración y rotación dinámica en lugar de claves de API codificadas de forma fija para limitar el radio de explosión si las credenciales quedan expuestas.
Flujo de Trabajo de Integración de API Paso a Paso
Una secuencia de integración definida garantiza un monitoreo estable de transacciones, un mapeo preciso de datos y un enrutamiento de reserva que previene la degradación del servicio durante la congestión de la red. Seguir patrones de implementación estándar permite a los desarrolladores vincular los libros de órdenes internos con las redes externas de cumplimiento de forma segura.
Paso 1: Gestión Segura de Autenticación y Claves de API
La fase de configuración comienza con la definición del límite de autenticación. Almacenar las credenciales de API directamente en los archivos de configuración de la aplicación introduce vulnerabilidades inmediatas. Los equipos de ingeniería configuran servicios de vault seguros, como HashiCorp Vault o AWS Secrets Manager, para obtener credenciales en tiempo de ejecución. Para plataformas que admiten autenticación avanzada, el uso de OIDC (OpenID Connect) o pares de claves RSA para la firma de solicitudes genera pruebas verificables del origen del payload. Configurar la rotación automatizada de claves de API dentro de los pipelines de CI/CD mantiene la seguridad de acceso sin tareas operativas manuales, bloqueando tokens obsoletos para que no accedan al backend de cumplimiento.
Paso 2: Mapeo de Datos de Transacciones Internas a Endpoints AML/KYT
La tarea de ingeniería principal requiere traducir los esquemas de bases de datos internas al formato específico que el proveedor de cumplimiento requiere. Este mapeo implica escribir middleware que extrae entradas de transacciones de los libros de contabilidad locales, las formatea según las especificaciones objetivo y las enruta hacia los endpoints de API AML/KYT relevantes. Para mejorar el rendimiento general, los desarrolladores configuran cron jobs para el procesamiento por lotes de registros históricos, manteniendo las llamadas a la API síncronas restringidas a las verificaciones de retiro previas a la transacción. Recurrir a plataformas establecidas como BlockSec reduce este ciclo de ingeniería, ya que sus esquemas de API aceptan variables multi-chain estándar, reduciendo el trabajo necesario de mapeo de middleware en aproximadamente un 40%.
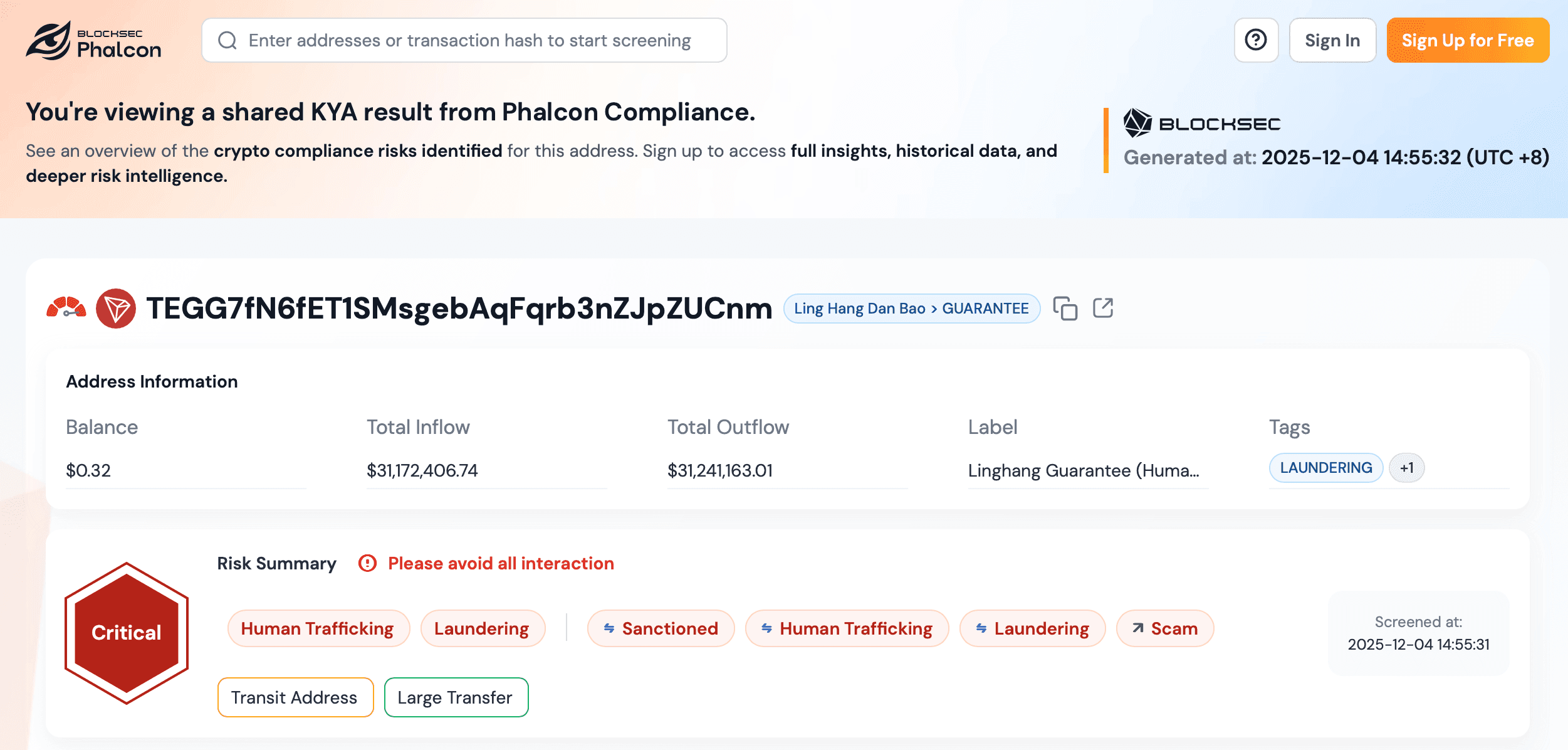
Paso 3: Habilitación de Monitor para Alertas Continuas de Riesgo de Direcciones
El filtrado KYT inicial solo captura el estado de riesgo de una dirección en el momento de la llamada. Para cubrir el caso en que una dirección previamente limpia interactúe posteriormente con una entidad marcada, los desarrolladores habilitan la función Monitor en las direcciones que requieren supervisión continua — por ejemplo, direcciones de depósito de usuarios de alto valor, billeteras calientes o contrapartes de grandes operaciones OTC. Monitor puede habilitarse desde la página de detalles de la dirección, el menú de acciones de la lista de direcciones o de forma programática a través de los endpoints de gestión de Monitor en Precios y Uso → Gestión de Datos → Monitores. Una vez habilitada, la dirección muestra una insignia de estado Monitoreando, y la plataforma la re-analiza con una frecuencia dinámica. Las alertas se activan únicamente ante transiciones reales de estado de riesgo (una nueva regla activada, o una regla existente eliminada) y se entregan a través de los Canales de Notificación ya configurados para la cuenta, lo que mantiene el backend del integrador libre de bucles de polling o manejo de eventos duplicados. La capacidad está regida por el plan: Essential y Scale incluyen 1 dirección monitoreada con niveles adicionales de pago (10 / 20 / 40 / 80 / 120 / 200), las cuentas Free y Credits obtienen una prueba única de 7 días, y los contratos Enterprise definen capacidad personalizada.
Paso 4: Actuación sobre las Respuestas de Riesgo de la API con Lógica de Manejo Downstream
Una vez que la API de cumplimiento devuelve una evaluación de riesgo para una transacción o dirección, el proveedor de servicios integrador es responsable de traducir ese resultado en acciones downstream concretas. La respuesta de la API en sí no bloquea ni mueve fondos — solo reporta la clasificación de riesgo, las reglas activadas y los metadatos asociados. Los equipos de ingeniería construyen una capa de decisión dedicada que consume esta respuesta y mapea cada nivel de riesgo a una acción operativa predefinida.
Las acciones downstream típicas incluyen:
-
Reembolsar depósitos entrantes identificados como provenientes de direcciones sancionadas o de alto riesgo, devolviendo los activos a la dirección de origen antes de que se acrediten al saldo interno del usuario.
-
Congelar la cuenta de usuario afectada o el saldo de la billetera, suspendiendo retiros y operaciones hasta que se complete la revisión manual.
-
Enrutar la transacción a una cola de revisión manual, donde los responsables de cumplimiento inspeccionan las reglas activadas y deciden si liberar, rechazar o escalar el caso.
-
Bloquear la solicitud de retiro saliente en la etapa previa a la difusión cuando la dirección de destino tiene una puntuación de riesgo inaceptable.
Cada acción debe activarse de forma idempotente basándose en el payload de respuesta de la API (y cualquier alerta posterior de Monitor para la misma dirección), con registro de auditoría completo para que cada decisión automatizada pueda reconstruirse para los informes regulatorios.
Errores Comunes de Integración y Solución de Problemas
Los equipos de ingeniería enfrentan regularmente problemas operativos que incluyen limitación de tasa de API, reorganizaciones de cadena y tasas elevadas de falsos positivos, que requieren ajustes programáticos. Escribir una lógica estricta de manejo de errores y modificar los parámetros de riesgo mantiene los sistemas automatizados precisos y estables durante los períodos de alta transacción.
Mitigación de Límites de Tasa de API y Cuellos de Botella de Alta Latencia
Alcanzar los límites de tasa de API ocurre con frecuencia durante la volatilidad del mercado cuando las colas de transacciones se expanden. Cuando la infraestructura alcanza un límite, la API del proveedor devuelve una respuesta HTTP 429 Too Many Requests. Para solucionar esto, los ingenieros construyen capas de throttling del lado del cliente y caché local para valores estáticos, como direcciones de contratos previamente verificadas. Configurar Redis o Memcached para almacenar puntuaciones de riesgo recientes reduce las solicitudes HTTP salientes duplicadas. Configurar hilos de workers paralelos y ajustar el connection pooling de la base de datos garantiza que el sistema maximice el rendimiento disponible sin superar los límites estrictos del proveedor externo.
Reducción de Falsos Positivos Mediante Reglas de Puntuación de Riesgo Personalizadas
Los algoritmos de riesgo predeterminados frecuentemente devuelven falsos positivos, restringiendo los retiros de usuarios estándar y aumentando los tickets de soporte manual. Los equipos técnicos ajustan los parámetros de puntuación de riesgo on-chain pasando variables de metadatos específicas a través del cuerpo de la API. Al cruzar las señales de riesgo externas con los análisis de sesión internos, el sistema aplica declaraciones condicionales para anular las reglas estrictas en cuentas institucionales establecidas y verificadas. Establecer límites de umbral locales permite al equipo de desarrollo ajustar la sensibilidad de las alertas, ayudando a los filtros del backend a distinguir entre transferencias maliciosas reales e interacciones estándar con contratos inteligentes.
Optimizaciones Técnicas Avanzadas para Pipelines de Datos
Escalar una configuración de cumplimiento requiere ingeniería de datos, integración de pipelines CI/CD, análisis basado en grafos y consideraciones de alojamiento localizado. Aplicar métodos de despliegue estándar permite a los equipos técnicos analizar datos del libro mayor mientras aplican seguridad operativa estricta y control de datos.
Automatización de Flujos de Trabajo de Escalación mediante Pipelines CI/CD
Actualizar las reglas de cumplimiento requiere agregar pruebas unitarias y de integración al pipeline de despliegue. Cuando los ingenieros de backend modifican parámetros de riesgo o actualizan la lógica de análisis de API, el nuevo código se ejecuta contra conjuntos de datos de transacciones históricas en un entorno de staging. Los equipos escriben scripts de Jenkins o GitHub Actions para ejecutar estas pruebas de regresión automáticamente. Si un commit de código genera un aumento anormal en las transacciones marcadas durante la simulación, el pipeline bloquea la solicitud de merge. Esta configuración de infraestructura como código verifica que las modificaciones al motor de riesgo superen la validación matemática antes del despliegue en producción.
Aprovechamiento de Estructuras de Datos de Grafos para el Análisis Profundo de Billeteras
El seguimiento de patrones de ofuscación de criptomonedas, incluidos los mezcladores de monedas o los puentes cross-chain, lleva a las bases de datos relacionales más allá de sus límites de consulta. Las integraciones de ingeniería frecuentemente utilizan herramientas de bases de datos de grafos (p. ej., Neo4j) para mapear transacciones de múltiples saltos y vínculos entre entidades. Al sincronizar la inteligencia de cumplimiento externa con un esquema de grafo local, los desarrolladores ejecutan consultas multicapa con baja latencia. Las herramientas desarrolladas por BlockSec admiten exportaciones de datos basadas en grafos, lo que permite a los equipos de backend rastrear rutas de ejecución algorítmica a través de nodos conectados e identificar patrones de amenaza programados sin una gran sobrecarga computacional.
Evaluación de Despliegues en Entornos Privados para la Soberanía de Datos
Para las organizaciones sujetas a leyes locales de soberanía de datos, el envío de registros de transacciones internos a APIs en la nube de múltiples inquilinos está restringido. En estos casos, los equipos de ingeniería aprovisionan configuraciones de entorno privado o en las instalaciones. Esto requiere alojar las instancias de nodo del proveedor de cumplimiento y los contenedores de análisis dentro de clústeres de Kubernetes localizados o nubes privadas virtuales (VPCs) restringidas. Si bien esta configuración aumenta el mantenimiento operativo requerido para la aplicación de parches de software y la sincronización de datos históricos, proporciona una garantía matemática de que los metadatos específicos del libro mayor permanecen fuera de las rutas de internet público.
Preguntas Frecuentes Técnicas: Integración de Cumplimiento en Blockchain
Resolver preguntas técnicas estándar sobre latencia, ingesta de datos históricos, enrutamiento de API multi-chain y modelos de despliegue de infraestructura ayuda a los equipos de desarrollo empresarial en la planificación de sistemas. Estas respuestas de referencia describen los requisitos arquitectónicos para soportar operaciones de libro mayor de alto volumen y conformes con las normativas.
¿Cuánta latencia agrega el monitoreo KYT en tiempo real a las transacciones?
En arquitecturas que utilizan streaming gRPC y caché Redis, la latencia de consulta en tiempo real se mide entre 50 y 150 milisegundos. Si el backend depende de solicitudes de API REST síncronas enrutadas a través de zonas de disponibilidad distantes sin connection pooling, los tiempos de respuesta pueden superar los 500 milisegundos, lo que frecuentemente activa tiempos de espera de ejecución en los motores de matching de alta frecuencia.
¿Cuál es el método más eficiente para sincronizar datos históricos on-chain?
Para el análisis histórico, los ingenieros evitan la paginación REST estándar y solicitan exportaciones de datos en bloque. Enviar archivos Apache Parquet o CSV directamente a un data lake interno (como AWS S3 o Snowflake) permite la ingesta de datos en paralelo. Este enfoque evita los bloqueos por límite de tasa HTTP y reduce las horas de procesamiento total requeridas para la sincronización histórica inicial.
¿Cómo gestionamos el enrutamiento de cumplimiento multi-chain dentro de una única API?
Las plataformas de cumplimiento actuales proporcionan una capa de abstracción unificada. Los desarrolladores envían el payload JSON estándar e incluyen un entero network_id o chain_identifier específico. El balanceador de carga del proveedor externo lee esta variable y enruta la verificación al clúster de nodos correspondiente (p. ej., nodos compatibles con EVM versus nodos UTXO), devolviendo un esquema estandarizado independientemente del formato de blockchain objetivo.
¿Pueden las herramientas de inteligencia de cumplimiento desplegarse completamente en las instalaciones?
Sí. Los proveedores empresariales suministran paquetes de despliegue a través de imágenes Docker o Helm charts configurados para clústeres de Kubernetes locales. Esto aísla todo el procesamiento de transacciones y los cálculos de riesgo dentro de la subred privada de la organización, completamente desconectada de las puertas de enlace de internet público, cumpliendo con los estrictos requisitos regulatorios y de auditoría de privacidad de datos.
Conclusión
Configurar una API de cumplimiento blockchain requiere un diseño arquitectónico estructurado, configuraciones de seguridad específicas y resiliencia a nivel de aplicación. Al verificar la compatibilidad de protocolos, mapear los esquemas de datos con precisión y escribir código estricto de manejo de errores, los equipos técnicos evitan los límites operativos comunes. Las implementaciones que aprovechan las pruebas CI/CD, las consultas de bases de datos de grafos y las capas de caché estabilizan el rendimiento del sistema bajo carga. Integrar plataformas orientadas a desarrolladores como BlockSec permite a los departamentos de ingeniería configurar estos pipelines de API de manera eficiente, proporcionando las utilidades de backend necesarias para cumplir con las verificaciones regulatorias dentro de entornos activos de activos digitales.



