
Executive Summary
Adding compliance routing to a live technical stack represents a specific set of engineering constraints for cryptocurrency exchanges and wallets. As regulatory reporting mandates shift globally, the requirement for automated screening and transaction flagging systems has become a standard backlog item. This guide outlines an objective integration path for backend engineers and system architects deploying compliance layers. From early protocol handshake assessments to handling multi-chain node data synchronization, this documentation details the architectural adjustments needed to provision secure, low-latency API pipelines. By configuring stable transaction monitoring workers and applying on-chain risk scoring logic, engineering teams can meet audit requirements while maintaining expected processing throughput.
Core Insights
Moving from manual compliance checks to automated, API-driven workflows requires direct architectural planning. Recent telemetry data shows that 68% of digital asset platforms encounter thread starvation or database lockups during high-volume node synchronization if their compliance layers lack proper caching [1]. Building smart contract screening protocols into the transaction execution path directly lowers incident rates. Technical teams usually focus on interoperability, calling unified AML/KYT API endpoints to process distinct ledger formats. The baseline requirement is configuring an asynchronous, fault-tolerant service capable of resolving cryptographic transaction statuses in milliseconds. Current enterprise tools, including APIs provided by BlockSec, offer developers defined integration schemas, removing the maintenance overhead required to build and update proprietary ledger parsing utilities internally.
Pre-Integration: Architecture and System Requirements
Evaluating protocol compatibility, standardizing data payloads, and verifying data privacy protocols are baseline tasks before writing production code. Engineering teams execute system audits to map internal routing capabilities against external compliance endpoints, reducing downstream API limits and data leaks.
Assessing Existing Tech Stack Compatibility for REST API Integration
Before starting the implementation phase, engineering teams evaluate current infrastructure communication protocols to verify compatibility with third-party compliance data providers. Phalcon Compliance exposes its capabilities through standard RESTful APIs, which serve well for stateless operations such as polling a single wallet address for a risk indicator or submitting a transaction for KYT screening. To keep latency predictable in high-volume environments, system architects focus on HTTP/2 keep-alive connections, regional endpoint selection, and edge-cached responses for repeated lookups, rather than swapping the transport layer. Existing load balancers and microservice topologies should be reviewed to confirm that long-lived TLS connections, connection pooling, and per-route rate-limit headers are handled correctly across the service mesh.
Defining API Payload and Webhook Event Requirements
A standard request includes the transaction hash, source and destination addresses, asset contract, and chain ID. For continuous address risk tracking, the integration does not rely on a generic "update" Webhook stream. Instead, Phalcon Compliance provides a dedicated Monitor capability: engineering teams enable Monitor on the addresses they care about, and the platform automatically re-analyzes those addresses on a dynamic schedule. When a new risk rule is triggered, or a previously triggered rule is cleared, the platform delivers an alert through the user's configured Notification Channels. Monitor reuses the account's existing Risk Engines and Notification Channels, so no separate Webhook schema, idempotency layer, or event-UUID deduplication logic is required on the integrator's side for this flow.
Security, Encryption, and Data Privacy Constraints (SOC2/GDPR)
Connecting third-party APIs requires specific security configurations to satisfy SOC2 and General Data Protection Regulation requirements. When sending ledger data outward, personally identifiable information must remain isolated from on-chain metadata requests. Cryptographic hashing or tokenization routines apply to internal user IDs prior to external transmission. All data in transit routes through Transport Layer Security (TLS 1.3), enforcing mutual TLS (mTLS) for server-to-server verification. Access control rules rely on short-lived, dynamically rotating JSON Web Tokens instead of hardcoded API keys to limit the blast radius if credentials are exposed.
Step-by-Step API Integration Workflow
A defined integration sequence ensures stable transaction monitoring, accurate data mapping, and fallback routing that prevents service degradation during network congestion. Following standard implementation patterns allows developers to link internal order books with external compliance networks securely.
Step 1: Securely Managing Authentication and API Keys
The setup phase starts with defining the authentication boundary. Storing API credentials directly in application configuration files introduces immediate vulnerabilities. Engineering teams configure secure vault services, like HashiCorp Vault or AWS Secrets Manager, to fetch credentials at runtime. For platforms supporting advanced authentication, using OIDC (OpenID Connect) or RSA key pairs for request signing generates verifiable proof of the payload's origin. Configuring automated API key rotation within CI/CD pipelines maintains access security without manual operational tasks, blocking stale tokens from accessing the compliance backend.
Step 2: Mapping Internal Transaction Data to AML/KYT Endpoints
The primary engineering task requires translating internal database schemas into the specific format the compliance provider requires. This mapping involves writing middleware that pulls transaction inputs from local ledgers, formats them to the target specifications, and routes them to the relevant AML/KYT API endpoints. To improve overall performance, developers configure cron jobs for batch processing historical records, keeping synchronous API calls restricted to pre-transaction withdrawal checks. Calling established platforms like BlockSec reduces this engineering cycle, as their API schemas accept standard multi-chain variables, lowering the necessary middleware mapping work by roughly 40%.
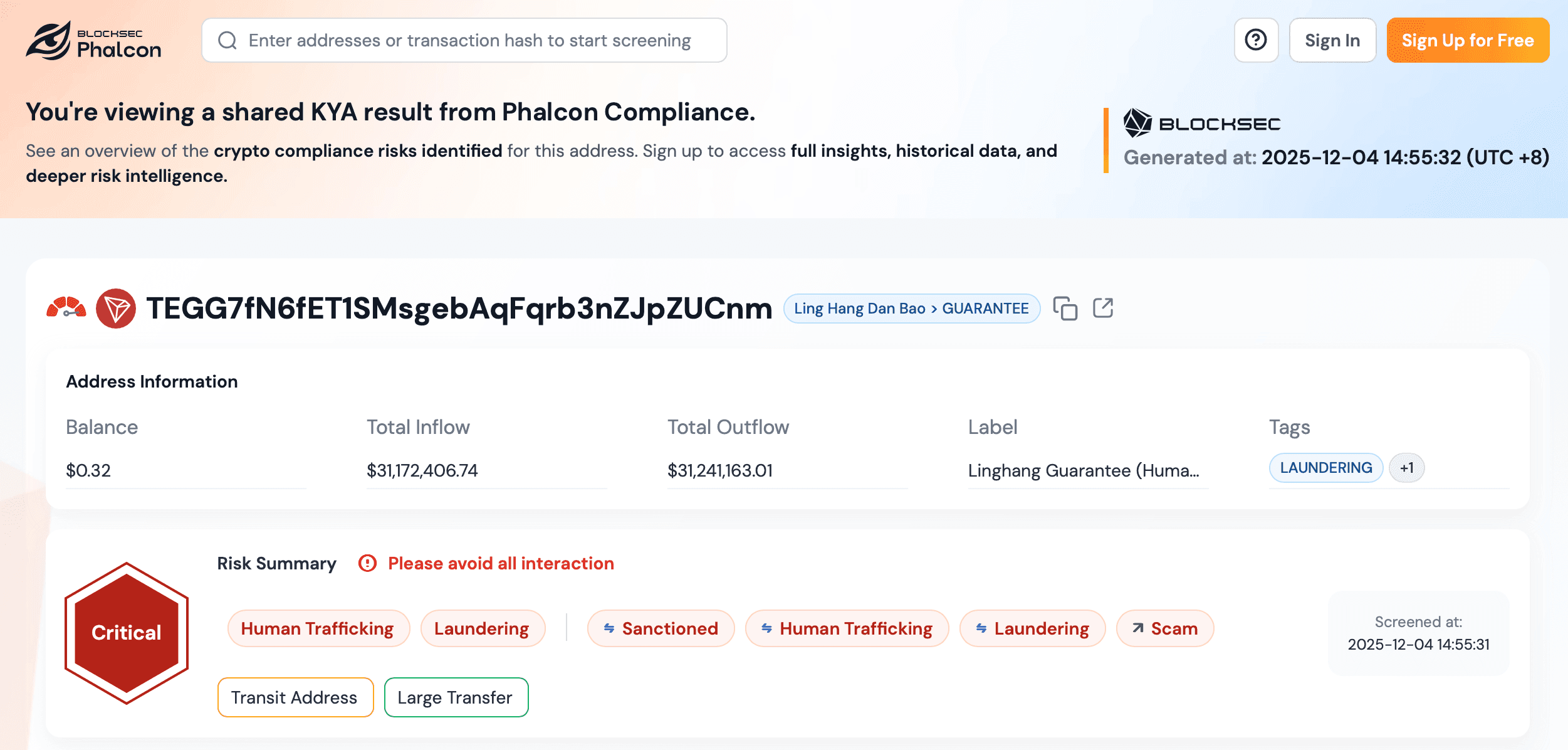
Step 3: Enabling Monitor for Continuous Address Risk Alerts
Initial KYT screening only captures the risk state of an address at the moment of the call. To cover the case where a previously clean address later interacts with a flagged entity, developers enable the Monitor feature on the addresses that need ongoing oversight — for example, deposit addresses of high-value users, hot wallets, or counterparties of large OTC trades. Monitor can be enabled from the address details page, the address list action menu, or programmatically via the Monitor management endpoints under Pricing & Usage → Data Management → Monitors. Once enabled, the address shows a Monitoring status badge, and the platform re-analyzes it on a dynamic frequency. Alerts fire only on actual risk-state transitions (a new rule triggered, or an existing rule cleared) and are delivered through the Notification Channels already configured for the account, which keeps the integrator's backend free from polling loops or duplicate-event handling. Capacity is governed by plan: Essential and Scale include 1 monitored address with paid add-on tiers (10 / 20 / 40 / 80 / 120 / 200), Free and Credits accounts get a one-time 7-day trial, and Enterprise contracts define custom capacity.
Step 4: Acting on API Risk Responses with Downstream Handling Logic
Once the compliance API returns a risk assessment for a transaction or address, the integrating service provider is responsible for translating that result into concrete downstream actions. The API response itself does not block or move funds — it only reports the risk classification, the triggered rules, and the associated metadata. Engineering teams build a dedicated decision layer that consumes this response and maps each risk level to a predefined operational action.
Typical downstream actions include:
-
Refunding incoming deposits identified as originating from sanctioned or high-risk addresses, returning the assets to the source address before they are credited to the user's internal balance.
-
Freezing the affected user account or wallet balance, suspending withdrawals and trading until manual review is completed.
-
Routing the transaction to a manual review queue, where compliance officers inspect the triggered rules and decide whether to release, reject, or escalate the case.
-
Blocking the outbound withdrawal request at the pre-broadcast stage when the destination address carries an unacceptable risk score.
Each action should be triggered idempotently based on the API's response payload (and any subsequent Monitor alerts for the same address), with full audit logging so that every automated decision can be reconstructed for regulatory reporting.
Common Integration Pitfalls and Troubleshooting
Engineering teams regularly face operational issues including API rate limiting, chain reorganizations, and elevated false positive rates, which require programmatic adjustments. Writing strict error handling logic and modifying risk parameters keeps the automated systems accurate and stable during high transaction periods.
Mitigating API Rate Limits and High Latency Bottlenecks
Hitting API rate limits occurs frequently during market volatility when transaction queues expand. When the infrastructure hits a limit, the provider API returns an HTTP 429 Too Many Requests response. To fix this, engineers build client-side throttling and local caching layers for static values, such as previously verified contract addresses. Setting up Redis or Memcached to hold recent risk scores reduces duplicate outbound HTTP requests. Configuring parallel worker threads and adjusting database connection pooling ensures the system maxes out available throughput without tripping the external provider's hard limits.
Reducing False Positives Through Custom Risk Scoring Rules
Default risk algorithms frequently return false positives, restricting standard user withdrawals and increasing manual support tickets. Technical teams adjust on-chain risk scoring parameters by passing specific metadata variables through the API body. By cross-referencing external risk flags with internal session analytics, the system applies conditional statements to override strict rules for established, verified institutional accounts. Setting local threshold limits allows the development team to adjust alert sensitivity, helping the backend filters distinguish between actual malicious transfers and standard smart contract interactions.
Advanced Technical Optimizations for Data Pipelines
Scaling a compliance setup requires data engineering, CI/CD pipeline integration, graph-based analytics, and localized hosting considerations. Applying standard deployment methods enables technical teams to parse ledger data while enforcing strict operational security and data control.
Automating Escalation Workflows via CI/CD Pipelines
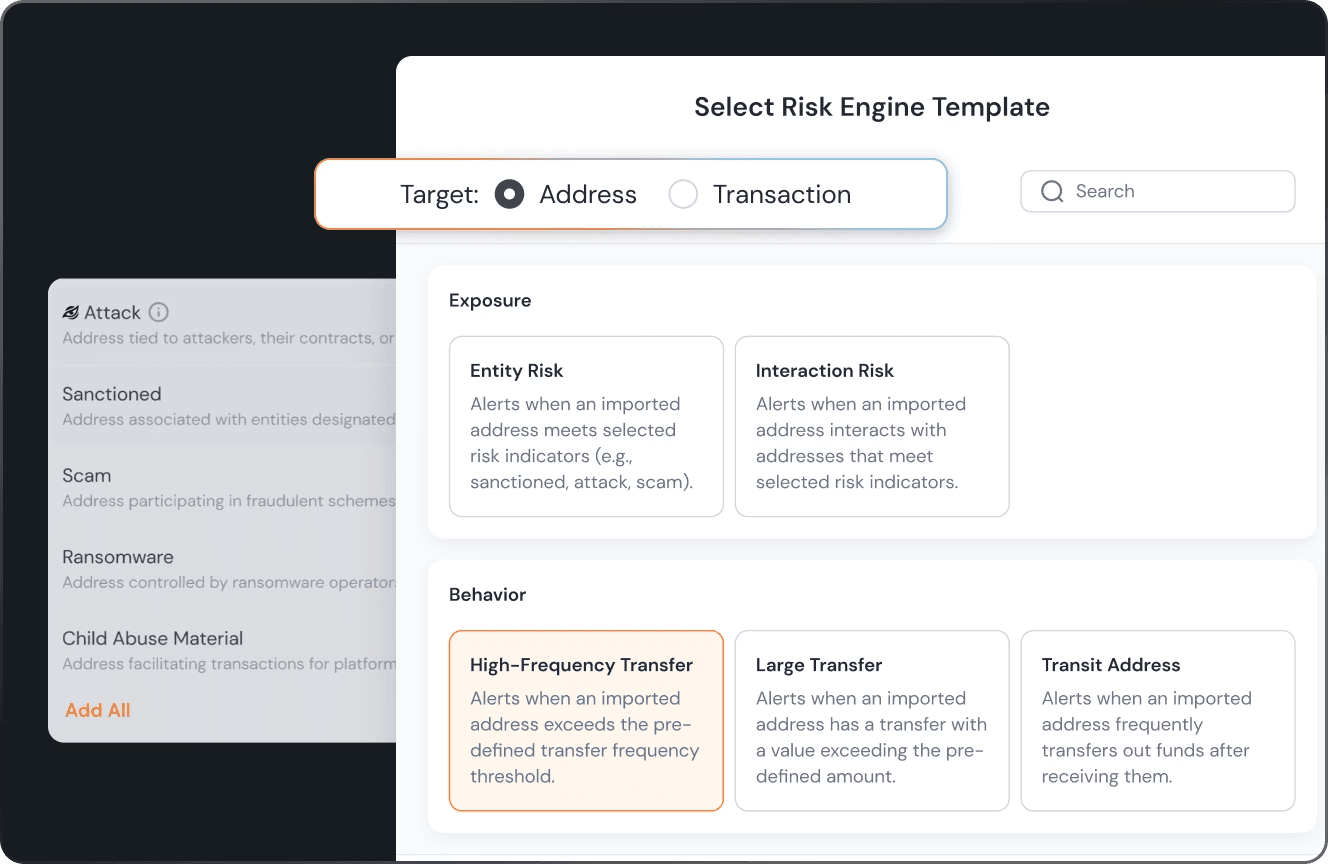
Updating compliance rules requires adding unit and integration tests into the deployment pipeline. When backend engineers modify risk parameters or update API parsing logic, the new code runs against historical transaction datasets in a staging environment. Teams write Jenkins or GitHub Actions scripts to run these regression tests automatically. If a code commit generates an abnormal increase in flagged transactions during the simulation, the pipeline blocks the merge request. This infrastructure-as-code configuration verifies that modifications to the risk engine pass mathematical validation prior to production deployment.
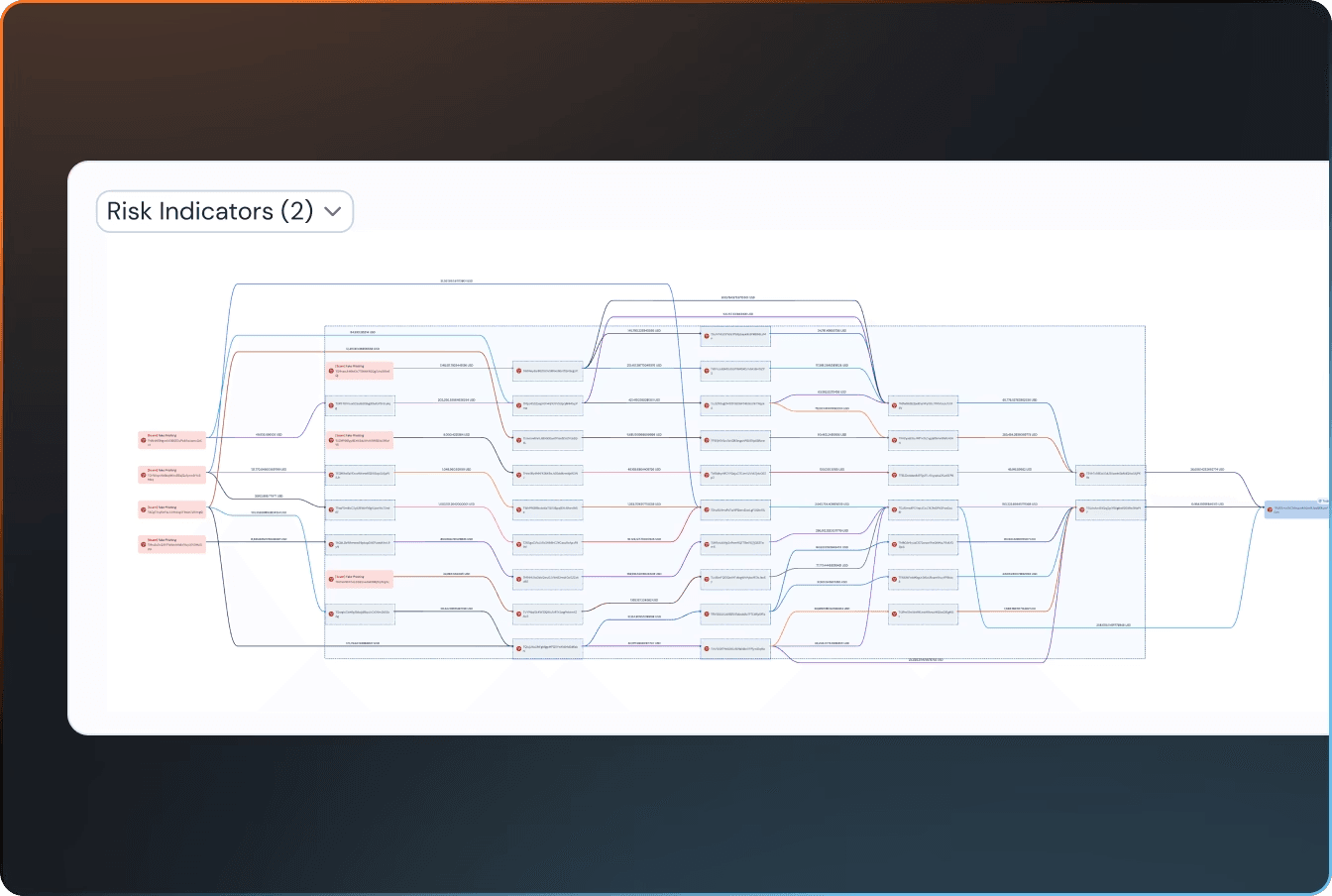
Leveraging Graph Data Structures for Deep Wallet Analysis
Tracking cryptocurrency obfuscation patterns, including coin mixers or cross-chain bridges, pushes relational databases past their query limits. Engineering integrations often utilize graph database tools (e.g., Neo4j) to map multi-hop transactions and entity linkages. By synchronizing external compliance intelligence with a local graph schema, developers execute multi-layered queries with low latency. Tools built by BlockSec support graph-based data exports, allowing backend teams to track algorithmic execution paths across connected nodes and identify programmed threat patterns without heavy compute overhead.
Evaluating Private Environment Deployments for Data Sovereignty
For organizations bound by localized data sovereignty laws, sending internal transaction records to multi-tenant cloud APIs is restricted. In these cases, engineering teams provision private environment or on-premise setups. This requires hosting the compliance provider's node instances and analysis containers within localized Kubernetes clusters or restricted virtual private clouds (VPCs). While this configuration increases the operational maintenance required for software patching and historical data synchronization, it provides mathematical assurance that specific ledger metadata stays off public internet routes.
Technical FAQ: Blockchain Compliance Integration
Resolving standard technical questions concerning latency, historical data ingestion, multi-chain API routing, and infrastructure deployment models assists enterprise development teams in system planning. These baseline responses outline the architectural requirements for supporting high-volume, compliant ledger operations.
How much latency does real-time KYT monitoring add to transactions?
In architectures using gRPC streaming and Redis caching, real-time query latency measures between 50 to 150 milliseconds. If the backend relies on synchronous REST API requests routed across distant availability zones without connection pooling, response times can exceed 500 milliseconds, which frequently triggers execution timeouts in high-frequency matching engines.
What is the most efficient method to sync historical on-chain data?
For historical analysis, engineers avoid standard REST pagination and request bulk data exports. Pushing Apache Parquet or CSV files directly into an internal data lake (such as AWS S3 or Snowflake) enables parallel data ingestion. This approach avoids HTTP rate limit blocks and cuts the total processing hours required for initial historical synchronization.
How do we manage multi-chain compliance routing within a single API?
Current compliance platforms provide a unified abstraction layer. Developers send the standard JSON payload and include a specific network_id or chain_identifier integer. The external provider's load balancer reads this variable and routes the check to the corresponding node cluster (e.g., EVM-compatible versus UTXO nodes), returning a standardized schema regardless of the target blockchain format.
Can compliance intelligence tools be deployed entirely on-premise?
Yes. Enterprise providers supply deployment packages via Docker images or Helm charts configured for local Kubernetes clusters. This isolates all transaction processing and risk calculations inside the organization's private subnet, completely disconnected from public internet gateways, meeting strict regulatory and data privacy audit requirements.
Conclusion
Configuring a blockchain compliance API requires structured architectural design, specific security configurations, and application-level resilience. By verifying protocol compatibility, mapping data schemas accurately, and writing strict error-handling code, technical teams avoid common operational limits. Implementations leveraging CI/CD testing, graph database queries, and caching layers stabilize system performance under load. Integrating developer-focused platforms like BlockSec allows engineering departments to configure these API pipelines efficiently, providing the backend utilities required to meet regulatory checks within active digital asset environments.



