
Zusammenfassung
Die Integration von Compliance-Routing in einen laufenden technischen Stack stellt Kryptowährungsbörsen und Wallets vor spezifische Engineering-Anforderungen. Da sich regulatorische Meldepflichten weltweit verschieben, ist der Bedarf an automatisierten Screening- und Transaktions-Flagging-Systemen zu einem standardmäßigen Backlog-Element geworden. Dieser Leitfaden beschreibt einen objektiven Integrationspfad für Backend-Ingenieure und Systemarchitekten, die Compliance-Schichten bereitstellen. Von frühen Protokoll-Handshake-Bewertungen bis zur Handhabung der Multi-Chain-Knoten-Datensynchronisierung beschreibt diese Dokumentation die architektonischen Anpassungen, die zur Bereitstellung sicherer API-Pipelines mit geringer Latenz erforderlich sind. Durch die Konfiguration stabiler Transaktionsüberwachungs-Worker und die Anwendung von On-Chain-Risikobewertungslogik können Engineering-Teams Prüfanforderungen erfüllen und gleichzeitig den erwarteten Verarbeitungsdurchsatz aufrechterhalten.
Kernerkenntnisse
Der Wechsel von manuellen Compliance-Prüfungen zu automatisierten, API-gesteuerten Workflows erfordert eine direkte architektonische Planung. Aktuelle Telemetriedaten zeigen, dass 68 % der Digital-Asset-Plattformen Thread-Starvation oder Datenbank-Sperren bei hochvolumiger Knotensynchronisierung erleben, wenn ihre Compliance-Schichten kein geeignetes Caching aufweisen [1]. Die Integration von Smart-Contract-Screening-Protokollen direkt in den Transaktionsausführungspfad senkt die Vorfallsraten. Technische Teams konzentrieren sich in der Regel auf Interoperabilität und rufen einheitliche AML/KYT-API-Endpunkte auf, um verschiedene Ledger-Formate zu verarbeiten. Die grundlegende Anforderung besteht darin, einen asynchronen, fehlertoleranten Dienst zu konfigurieren, der kryptografische Transaktionsstatus in Millisekunden auflösen kann. Aktuelle Enterprise-Tools, einschließlich der von BlockSec bereitgestellten APIs, bieten Entwicklern definierte Integrationsschemata und beseitigen den Wartungsaufwand, der für die interne Entwicklung und Aktualisierung proprietärer Ledger-Parsing-Dienstprogramme erforderlich wäre.
Vor der Integration: Architektur und Systemanforderungen
Die Bewertung der Protokollkompatibilität, die Standardisierung von Daten-Payloads und die Überprüfung von Datenschutzprotokollen sind grundlegende Aufgaben vor dem Schreiben von Produktionscode. Engineering-Teams führen Systemaudits durch, um interne Routing-Fähigkeiten mit externen Compliance-Endpunkten abzugleichen und so nachgelagerte API-Limits und Datenlecks zu reduzieren.
Bewertung der Kompatibilität des bestehenden Tech-Stacks für die REST-API-Integration
Vor Beginn der Implementierungsphase evaluieren Engineering-Teams die aktuellen Infrastruktur-Kommunikationsprotokolle, um die Kompatibilität mit Drittanbieter-Compliance-Datenanbietern zu überprüfen. Phalcon Compliance stellt seine Funktionen über Standard-RESTful-APIs bereit, die sich gut für zustandslose Operationen eignen, wie das Abfragen einer einzelnen Wallet-Adresse auf einen Risikoindikator oder das Einreichen einer Transaktion für das KYT-Screening. Um die Latenz in hochvolumigen Umgebungen vorhersehbar zu halten, konzentrieren sich Systemarchitekten auf HTTP/2-Keep-Alive-Verbindungen, regionale Endpunktauswahl und edge-gecachte Antworten für wiederholte Abfragen, anstatt die Transportschicht auszutauschen. Bestehende Load Balancer und Microservice-Topologien sollten überprüft werden, um sicherzustellen, dass langlebige TLS-Verbindungen, Connection Pooling und per-Route-Rate-Limit-Header im gesamten Service-Mesh korrekt behandelt werden.
Definition von API-Payload- und Webhook-Event-Anforderungen
Eine Standardanfrage enthält den Transaktions-Hash, Quell- und Zieladressen, den Asset-Vertrag und die Chain-ID. Für die kontinuierliche Adressrisikoverfolgung stützt sich die Integration nicht auf einen generischen „Update"-Webhook-Stream. Stattdessen bietet Phalcon Compliance eine dedizierte Monitor-Funktion: Engineering-Teams aktivieren Monitor für die Adressen, die sie überwachen möchten, und die Plattform analysiert diese Adressen automatisch nach einem dynamischen Zeitplan erneut. Wenn eine neue Risikoregel ausgelöst oder eine zuvor ausgelöste Regel aufgehoben wird, sendet die Plattform eine Benachrichtigung über die konfigurierten Benachrichtigungskanäle des Benutzers. Monitor verwendet die bestehenden Risk Engines und Benachrichtigungskanäle des Kontos, sodass auf der Seite des Integrators kein separates Webhook-Schema, keine Idempotenz-Schicht oder Ereignis-UUID-Deduplizierungslogik für diesen Ablauf erforderlich ist.
Sicherheits-, Verschlüsselungs- und Datenschutzbeschränkungen (SOC2/DSGVO)
Die Verbindung von Drittanbieter-APIs erfordert spezifische Sicherheitskonfigurationen, um SOC2- und Datenschutz-Grundverordnungsanforderungen zu erfüllen. Beim Senden von Ledger-Daten nach außen müssen personenbezogene Daten von On-Chain-Metadatenanfragen isoliert bleiben. Kryptografische Hash- oder Tokenisierungsverfahren werden auf interne Benutzer-IDs vor der externen Übertragung angewendet. Alle Daten während der Übertragung werden über Transport Layer Security (TLS 1.3) geleitet, wobei gegenseitiges TLS (mTLS) für die Server-zu-Server-Verifizierung erzwungen wird. Zugriffsregeln basieren auf kurzlebigen, dynamisch rotierenden JSON Web Tokens anstelle von fest codierten API-Schlüsseln, um den Schadensradius bei einer Kompromittierung von Anmeldedaten zu begrenzen.
Schrittweiser API-Integrations-Workflow
Eine definierte Integrationssequenz gewährleistet eine stabile Transaktionsüberwachung, genaue Datenzuordnung und Fallback-Routing, das Dienstverschlechterungen während Netzwerküberlastungen verhindert. Die Befolgung standardmäßiger Implementierungsmuster ermöglicht es Entwicklern, interne Orderbücher sicher mit externen Compliance-Netzwerken zu verknüpfen.
Schritt 1: Sichere Verwaltung von Authentifizierung und API-Schlüsseln
Die Einrichtungsphase beginnt mit der Definition der Authentifizierungsgrenze. Das direkte Speichern von API-Anmeldedaten in Anwendungskonfigurationsdateien führt zu sofortigen Schwachstellen. Engineering-Teams konfigurieren sichere Vault-Dienste wie HashiCorp Vault oder AWS Secrets Manager, um Anmeldedaten zur Laufzeit abzurufen. Für Plattformen, die erweiterte Authentifizierung unterstützen, erzeugt die Verwendung von OIDC (OpenID Connect) oder RSA-Schlüsselpaaren zur Anforderungssignierung einen überprüfbaren Nachweis über den Ursprung des Payloads. Die Konfiguration automatischer API-Schlüsselrotation innerhalb von CI/CD-Pipelines erhält die Zugriffssicherheit ohne manuelle Betriebsaufgaben und verhindert, dass veraltete Token auf das Compliance-Backend zugreifen.
Schritt 2: Zuordnung interner Transaktionsdaten zu AML/KYT-Endpunkten
Die primäre Engineering-Aufgabe erfordert die Übersetzung interner Datenbankschemata in das spezifische Format, das der Compliance-Anbieter benötigt. Diese Zuordnung umfasst das Schreiben von Middleware, die Transaktionseingaben aus lokalen Ledgern abruft, sie nach den Zielspezifikationen formatiert und an die relevanten AML/KYT-API-Endpunkte weiterleitet. Um die Gesamtleistung zu verbessern, konfigurieren Entwickler Cron-Jobs für die Batch-Verarbeitung historischer Datensätze und halten synchrone API-Aufrufe auf Pre-Transaktions-Auszahlungsprüfungen beschränkt. Der Aufruf etablierter Plattformen wie BlockSec reduziert diesen Engineering-Zyklus, da ihre API-Schemata standardmäßige Multi-Chain-Variablen akzeptieren und den erforderlichen Middleware-Zuordnungsaufwand um etwa 40 % verringern.
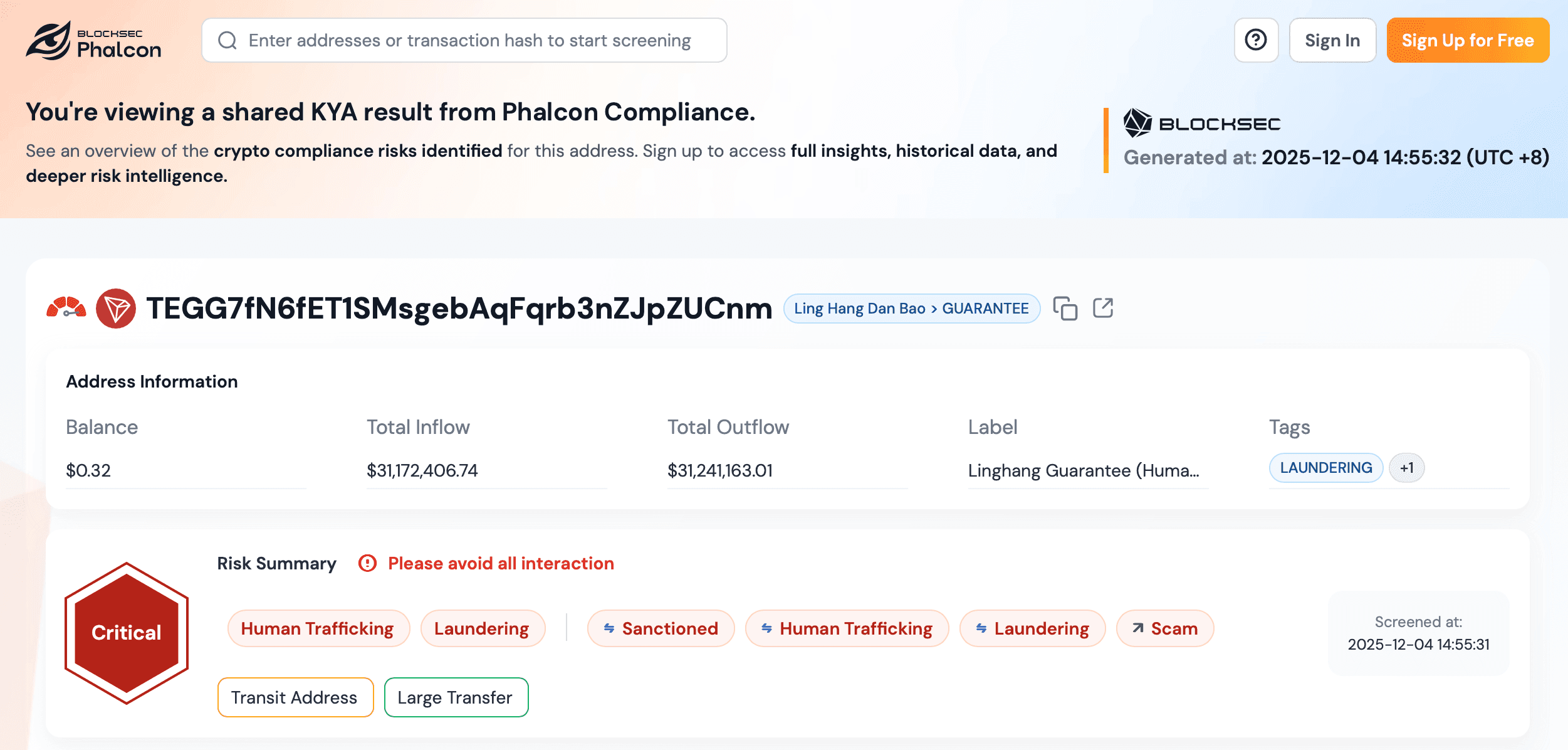
Schritt 3: Aktivierung von Monitor für kontinuierliche Adressrisikobenachrichtigungen
Das anfängliche KYT-Screening erfasst nur den Risikostatus einer Adresse zum Zeitpunkt des Aufrufs. Um den Fall abzudecken, dass eine zuvor saubere Adresse später mit einer markierten Entität interagiert, aktivieren Entwickler die Monitor-Funktion für Adressen, die einer kontinuierlichen Überwachung bedürfen – zum Beispiel Einzahlungsadressen von High-Value-Nutzern, Hot Wallets oder Gegenparteien großer OTC-Trades. Monitor kann über die Adressdetailseite, das Aktionsmenü der Adressliste oder programmgesteuert über die Monitor-Verwaltungsendpunkte unter Preise & Nutzung → Datenverwaltung → Monitore aktiviert werden. Nach der Aktivierung zeigt die Adresse ein Überwachungs-Statusabzeichen, und die Plattform analysiert sie mit dynamischer Häufigkeit erneut. Benachrichtigungen werden nur bei tatsächlichen Risikozustandsübergängen ausgelöst (eine neue Regel ausgelöst oder eine bestehende Regel aufgehoben) und werden über die bereits für das Konto konfigurierten Benachrichtigungskanäle zugestellt, wodurch das Backend des Integrators frei von Polling-Schleifen oder der Handhabung doppelter Ereignisse bleibt. Die Kapazität wird durch den Plan geregelt: Essential und Scale beinhalten 1 überwachte Adresse mit kostenpflichtigen Add-on-Stufen (10 / 20 / 40 / 80 / 120 / 200), Free- und Credits-Konten erhalten einen einmaligen 7-Tage-Test, und Enterprise-Verträge definieren individuelle Kapazitäten.
Schritt 4: Reaktion auf API-Risikoantworten mit nachgelagerter Verarbeitungslogik
Sobald die Compliance-API eine Risikobewertung für eine Transaktion oder Adresse zurückgibt, ist der integrierende Dienstleister dafür verantwortlich, dieses Ergebnis in konkrete nachgelagerte Aktionen umzusetzen. Die API-Antwort selbst blockiert oder bewegt keine Gelder – sie meldet nur die Risikoklassifizierung, die ausgelösten Regeln und die zugehörigen Metadaten. Engineering-Teams bauen eine dedizierte Entscheidungsschicht auf, die diese Antwort verarbeitet und jede Risikostufe einer vordefinierten operativen Aktion zuordnet.
Typische nachgelagerte Aktionen umfassen:
-
Rückerstattung eingehender Einzahlungen, die als von sanktionierten oder risikoreichen Adressen stammend identifiziert wurden, wobei die Assets an die Quelladresse zurückgegeben werden, bevor sie dem internen Guthaben des Nutzers gutgeschrieben werden.
-
Einfrieren des betroffenen Benutzerkontos oder Wallet-Guthabens, Aussetzung von Auszahlungen und Handel bis zur Abschluss der manuellen Überprüfung.
-
Weiterleitung der Transaktion an eine manuelle Überprüfungswarteschlange, wo Compliance-Beauftragte die ausgelösten Regeln prüfen und entscheiden, ob der Fall freigegeben, abgelehnt oder eskaliert werden soll.
-
Blockierung der ausgehenden Auszahlungsanforderung in der Pre-Broadcast-Phase, wenn die Zieladresse ein unakzeptables Risikoniveau aufweist.
Jede Aktion sollte idempotent basierend auf dem API-Antwort-Payload (und etwaigen nachfolgenden Monitor-Benachrichtigungen für dieselbe Adresse) ausgelöst werden, mit vollständiger Audit-Protokollierung, sodass jede automatisierte Entscheidung für regulatorische Berichte rekonstruiert werden kann.
Häufige Integrationsprobleme und Fehlerbehebung
Engineering-Teams stehen regelmäßig vor betrieblichen Problemen, darunter API-Rate-Limiting, Chain-Reorganisierungen und erhöhte False-Positive-Raten, die programmatische Anpassungen erfordern. Das Schreiben strenger Fehlerbehandlungslogik und die Anpassung von Risikoparametern hält die automatisierten Systeme während hoher Transaktionsperioden genau und stabil.
Minderung von API-Rate-Limits und Engpässen mit hoher Latenz
Das Erreichen von API-Rate-Limits tritt häufig während der Marktvolatilität auf, wenn Transaktionswarteschlangen sich ausdehnen. Wenn die Infrastruktur ein Limit erreicht, gibt die Anbieter-API eine HTTP-429-Too-Many-Requests-Antwort zurück. Um dies zu beheben, bauen Ingenieure clientseitige Drosselung und lokale Caching-Schichten für statische Werte auf, wie zuvor verifizierte Vertragsadressen. Die Einrichtung von Redis oder Memcached zur Speicherung aktueller Risikobewertungen reduziert doppelte ausgehende HTTP-Anfragen. Die Konfiguration paralleler Worker-Threads und die Anpassung des Datenbank-Connection-Poolings stellen sicher, dass das System den verfügbaren Durchsatz maximiert, ohne die harten Limits des externen Anbieters zu überschreiten.
Reduzierung von False Positives durch benutzerdefinierte Risikobewertungsregeln
Standard-Risikoalgorithmen liefern häufig False Positives, schränken Standard-Benutzerauszahlungen ein und erhöhen manuelle Support-Tickets. Technische Teams passen On-Chain-Risikobewertungsparameter an, indem sie spezifische Metadatenvariablen über den API-Body übergeben. Durch die Querverknüpfung externer Risikomarkierungen mit internen Session-Analysen wendet das System bedingte Anweisungen an, um strenge Regeln für etablierte, verifizierte institutionelle Konten außer Kraft zu setzen. Die Festlegung lokaler Schwellenwerte ermöglicht es dem Entwicklungsteam, die Benachrichtigungsempfindlichkeit anzupassen und den Backend-Filtern zu helfen, zwischen tatsächlich bösartigen Transfers und standardmäßigen Smart-Contract-Interaktionen zu unterscheiden.
Erweiterte technische Optimierungen für Datenpipelines
Die Skalierung eines Compliance-Setups erfordert Data Engineering, CI/CD-Pipeline-Integration, graphbasierte Analysen und Überlegungen zum lokalisierten Hosting. Die Anwendung standardmäßiger Bereitstellungsmethoden ermöglicht es technischen Teams, Ledger-Daten zu analysieren und dabei strenge operative Sicherheit und Datenkontrolle durchzusetzen.
Automatisierung von Eskalations-Workflows über CI/CD-Pipelines
Die Aktualisierung von Compliance-Regeln erfordert das Hinzufügen von Unit- und Integrationstests in die Deployment-Pipeline. Wenn Backend-Ingenieure Risikoparameter ändern oder API-Parsing-Logik aktualisieren, wird der neue Code gegen historische Transaktionsdatensätze in einer Staging-Umgebung ausgeführt. Teams schreiben Jenkins- oder GitHub-Actions-Skripte, um diese Regressionstests automatisch auszuführen. Wenn ein Code-Commit während der Simulation einen abnormalen Anstieg markierter Transaktionen erzeugt, blockiert die Pipeline den Merge-Request. Diese Infrastructure-as-Code-Konfiguration stellt sicher, dass Änderungen an der Risk Engine eine mathematische Validierung bestehen, bevor sie in der Produktion eingesetzt werden.
Nutzung von Graphdatenstrukturen für tiefgreifende Wallet-Analysen
Das Verfolgen von Kryptowährungs-Verschleierungsmustern, einschließlich Coin-Mixer oder Cross-Chain-Bridges, überfordert relationale Datenbanken bei ihren Abfragelimits. Engineering-Integrationen nutzen häufig Graph-Datenbank-Tools (z. B. Neo4j), um Multi-Hop-Transaktionen und Entitätsverknüpfungen abzubilden. Durch die Synchronisierung externer Compliance-Intelligence mit einem lokalen Graph-Schema führen Entwickler mehrschichtige Abfragen mit geringer Latenz aus. Von BlockSec entwickelte Tools unterstützen graphbasierte Datenexporte, sodass Backend-Teams algorithmische Ausführungspfade über verbundene Knoten verfolgen und programmierte Bedrohungsmuster ohne hohen Rechenaufwand identifizieren können.
Bewertung privater Umgebungsbereitstellungen für Datensouveränität
Für Organisationen, die an lokalisierte Datensouveränitätsgesetze gebunden sind, ist das Senden interner Transaktionsdatensätze an Multi-Tenant-Cloud-APIs eingeschränkt. In diesen Fällen richten Engineering-Teams private Umgebungs- oder On-Premise-Setups ein. Dies erfordert das Hosting der Knoten-Instanzen und Analyse-Container des Compliance-Anbieters innerhalb lokalisierter Kubernetes-Cluster oder eingeschränkter Virtual Private Clouds (VPCs). Obwohl diese Konfiguration den betrieblichen Wartungsaufwand für Software-Patching und historische Datensynchronisierung erhöht, bietet sie mathematische Gewissheit, dass spezifische Ledger-Metadaten außerhalb öffentlicher Internetrouten bleiben.
Technische FAQ: Blockchain-Compliance-Integration
Die Beantwortung standardmäßiger technischer Fragen zu Latenz, historischer Datenaufnahme, Multi-Chain-API-Routing und Infrastruktur-Bereitstellungsmodellen unterstützt Enterprise-Entwicklungsteams bei der Systemplanung. Diese grundlegenden Antworten beschreiben die architektonischen Anforderungen zur Unterstützung hochvolumiger, konformer Ledger-Operationen.
Wie viel Latenz fügt die Echtzeit-KYT-Überwachung zu Transaktionen hinzu?
In Architekturen, die gRPC-Streaming und Redis-Caching verwenden, liegt die Echtzeit-Abfragelatenz zwischen 50 und 150 Millisekunden. Wenn das Backend auf synchrone REST-API-Anfragen angewiesen ist, die über entfernte Verfügbarkeitszonen ohne Connection Pooling geleitet werden, können die Antwortzeiten 500 Millisekunden überschreiten, was häufig Ausführungs-Timeouts in hochfrequenten Matching-Engines auslöst.
Was ist die effizienteste Methode zur Synchronisierung historischer On-Chain-Daten?
Für historische Analysen vermeiden Ingenieure Standard-REST-Paginierung und fordern stattdessen Bulk-Datenexporte an. Das direkte Übertragen von Apache-Parquet- oder CSV-Dateien in einen internen Data Lake (wie AWS S3 oder Snowflake) ermöglicht eine parallele Datenaufnahme. Dieser Ansatz vermeidet HTTP-Rate-Limit-Blockierungen und reduziert die gesamten Verarbeitungsstunden, die für die anfängliche historische Synchronisierung erforderlich sind.
Wie verwalten wir Multi-Chain-Compliance-Routing innerhalb einer einzigen API?
Aktuelle Compliance-Plattformen bieten eine einheitliche Abstraktionsschicht. Entwickler senden den Standard-JSON-Payload und fügen eine spezifische network_id- oder chain_identifier-Ganzzahl hinzu. Der Load Balancer des externen Anbieters liest diese Variable und leitet die Prüfung an den entsprechenden Knoten-Cluster weiter (z. B. EVM-kompatibel gegenüber UTXO-Knoten) und gibt ein standardisiertes Schema zurück, unabhängig vom Ziel-Blockchain-Format.
Können Compliance-Intelligence-Tools vollständig On-Premise bereitgestellt werden?
Ja. Enterprise-Anbieter stellen Bereitstellungspakete über Docker-Images oder Helm-Charts bereit, die für lokale Kubernetes-Cluster konfiguriert sind. Dadurch wird die gesamte Transaktionsverarbeitung und Risikoberechnung innerhalb des privaten Subnetzes der Organisation isoliert, vollständig von öffentlichen Internet-Gateways getrennt, und strenge regulatorische und Datenschutz-Prüfungsanforderungen werden erfüllt.
Fazit
Die Konfiguration einer Blockchain-Compliance-API erfordert strukturiertes architektonisches Design, spezifische Sicherheitskonfigurationen und Resilienz auf Anwendungsebene. Durch die Überprüfung der Protokollkompatibilität, die genaue Zuordnung von Datenschemata und das Schreiben strenger Fehlerbehandlungscodes vermeiden technische Teams häufige betriebliche Limits. Implementierungen, die CI/CD-Tests, Graph-Datenbankabfragen und Caching-Schichten nutzen, stabilisieren die Systemleistung unter Last. Die Integration entwicklerorientierter Plattformen wie BlockSec ermöglicht es Engineering-Abteilungen, diese API-Pipelines effizient zu konfigurieren und die Backend-Dienstprogramme bereitzustellen, die erforderlich sind, um regulatorische Prüfungen in aktiven Digital-Asset-Umgebungen zu erfüllen.



